Architektura řešení
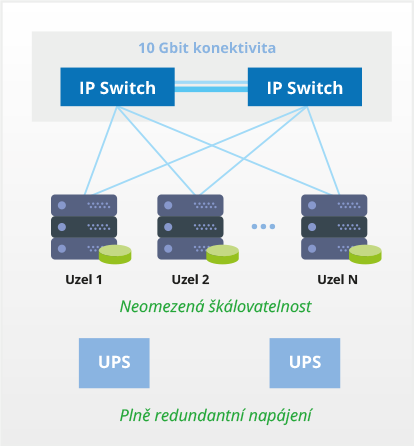
Celá architektura řešení Private Cloud je po HW stránce redundantní (zdvojená) a výpadek jakéhokoliv prvku systému neznamená výpadek poskytovaných služeb.
Každý uzel clusteru je zapojen dvěma síťovými kabely do dvou switchů, přičemž pro nedegradovaný režim běhu postačí funkční jedno připojení. Počet propojů je možné i zvyšovat, což vede nejen ke zvýšení redundance ale i ke zvýšení přenosového výkonu. Switche jsou zapojeny ve stohu, tedy všechy switche se chovají jako jeden celek. Stack propoj je rovněž řešen redundatně, tedy switche jsou zapojeny buď do kruhu, popř. je propojení switchů provedeno způsobem každý s každým.
Podobně redundatně je řešeno napájení – jak uzly, tak i switche jsou vybaveny redundantními zdroji a každý zdroj je zapojen do jiné UPS.
Jak to funguje – zabezpečení dat a provozu na uzlech clusteru
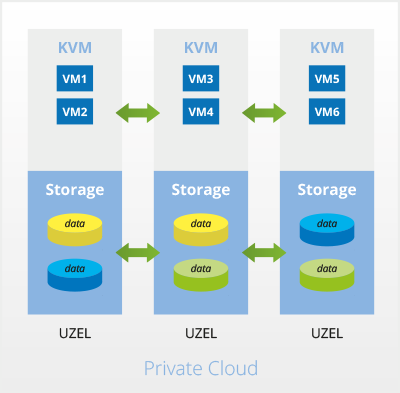
Korektní stav
Uzly Private Cloud pracují s daty tak, že v jednu chvíli jsou data uložena na minimálně dvou uzlech – tím je zabezpečeno, že v případě selhání jednoho z uzlů nedojde k žádné ztrátě dat.
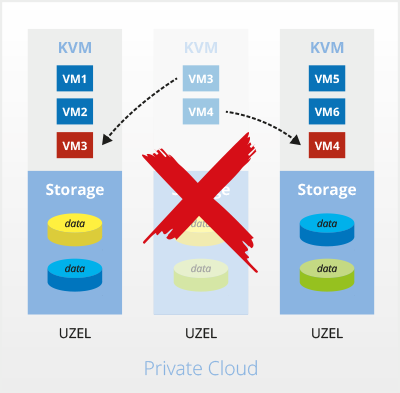
Výpadek jednoho prvku
Při výpadku serveru nedošlo ke ztrátě dat – data byla redundantně uložena na více serverech. Systém tuto funkci vzhledem k aplikacím zajišťuje tak, že vůbec nepoznají že se něco stalo a pokračují v provozu bez jakéhokoliv výpadku.
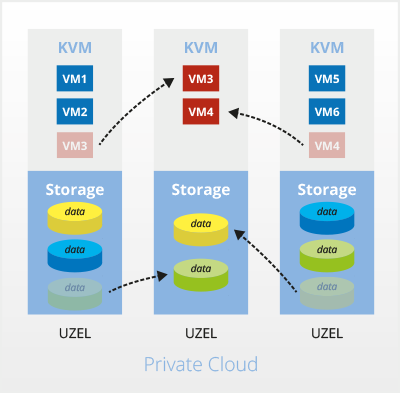
Obnovení korektního stavu po výpadku
Po opravě serveru se systém opět dostane do původního stavu – VM jsou přesunuty zpět na původní server, a data jsou uložena prokládaně mezi všechny servery v clusteru.
Private Cloud je odolný proti výpadku kterékoliv komponenty clusteru. Krom zajištění provozu v případě výpadku tato funkce usnadňuje správu celého systému – při plánované odstávce lze dělat údržbu za plného provozu. Stejně tak rozšiřování systému, migrace apod. se mohou provádět za plného provozu a s minimálním omezením výkonu.
Zabezpečení dat – redundance řešení
Redundance dat
Redundance vašich dat je zajištěna na úrovni online zrcadlení diskového prostoru mezi jednotlivými uzly v clusteru.
2 repliky – základní zabezpečení – data jsou uložena na dvou uzlech
výpadek jednoho uzlu nebo jednoho disku znamená jen krátkodobou ztrátu redundance (systém může zahájit proces resynchronizace dat na jiný uzel či disk)
3 repliky – vyšší zabezpečení – data jsou uložena na třech uzlech
výpadek jednoho uzlu nebo jednoho disku neznamená ztrátu redundance dat
výpadek dvou uzlů nebo dvou disků neznamená ztrátu dat
více replik – extrémní zabezpečení – v případě požadavku je data možné zrcadlit i na více než na 3 uzlech
Redundance síťové infrastruktury
Každý uzel clusteru je zapojen dvěma síťovými kabely do dvou switchů, přičemž pro nedegradovaný režim běhu postačí funkční jedno připojení. Počet propojů je možné i zvyšovat, což vede nejen ke zvýšení redundance ale i ke zvýšení přenosového výkonu.
Switche jsou zapojeny ve stohu, tedy všechy switche se chovají jako jeden celek. Stack propoj je rovněž řešen redundatně, tedy switche jsou zapojeny buď do kruhu, popř. je propojení switchů provedeno způsobem každý s každým.
Další prvky zvyšující dostupnost
- paměťové moduly typu ECC
- redundantní zdroje v uzlech clusteru
- redundantní zdroje ve switchích